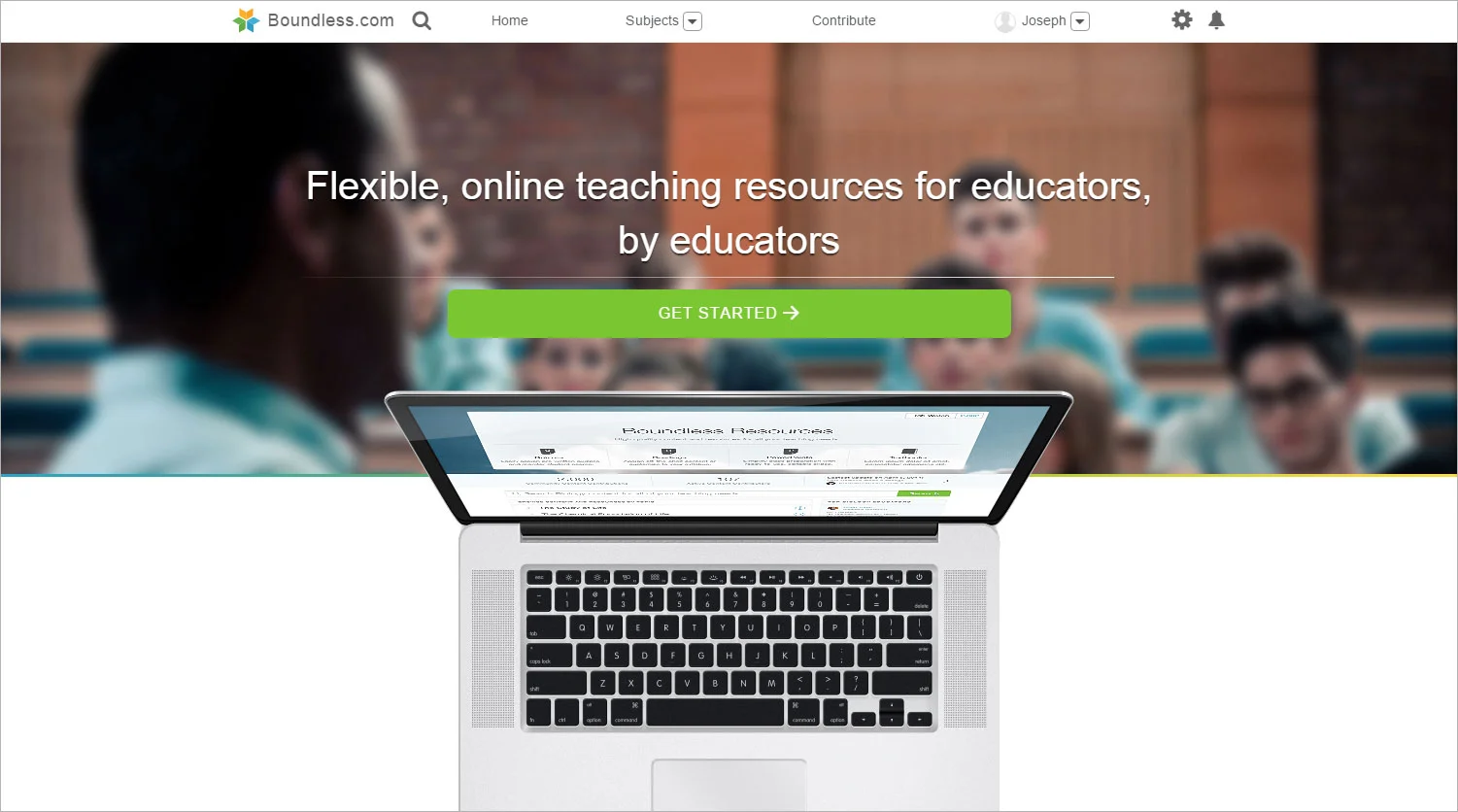
HashHype summarizes internet noise
HashHype is a web app to visualize trending topics in stocks, social, and news. It uses real-time natural language processing to select a single comment which best represents each trend. Users can quickly cut through the chatter and be the first to react. HashHype.com was inspired by the meme stock revolution, and the fact that reality is what we make it, for better or worse.






Is this just hash tags?
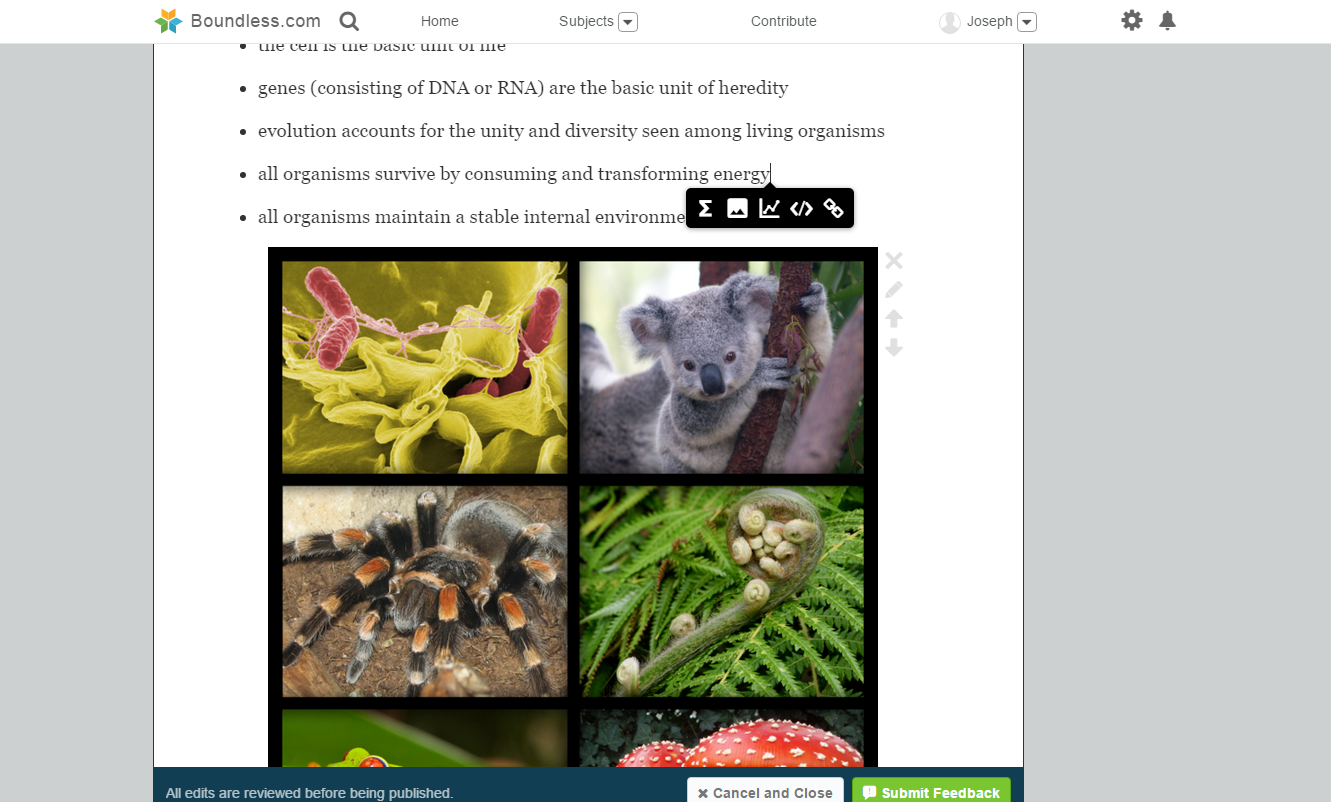
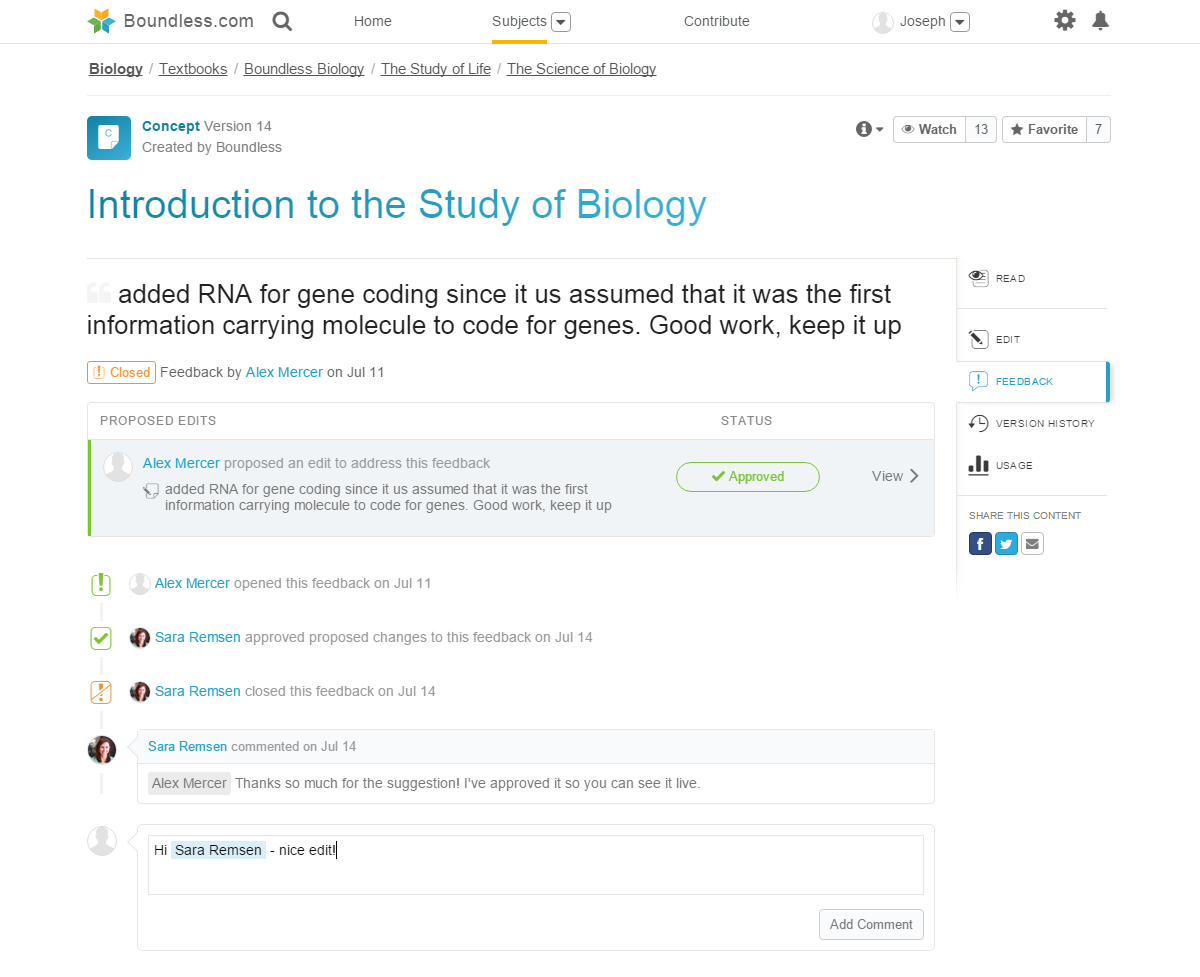
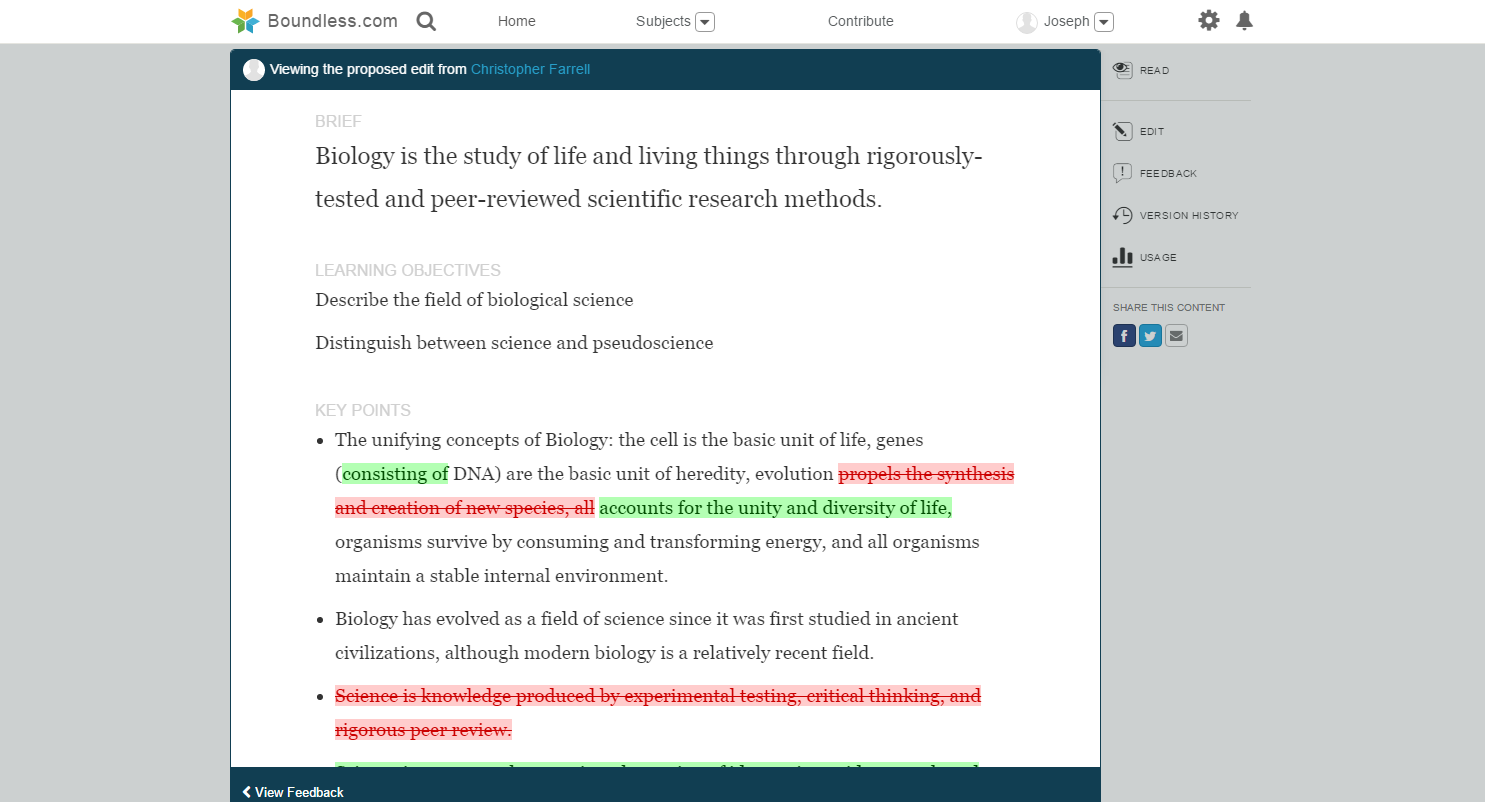
The HashHype algorithm goes way beyond just counting stock #ticker @mentions. It analyzes the entire comment, capturing context and sentiment from all words in each sentence. It understands word combos of different lengths, and then clusters of those word combos, respecting order and distance between combos in a cluster. HashHype also understands symbols like emojis, urls, stocks, others. Each aspect of this algorithm is illustrated in the UI so that users can understand the info in a clear and transparent manner.
While HashHype calculates the top ten trends at any given moment, it also snapshots each of those moments into a historical database. That historical data makes the algorithm more accurate as time goes on because trends with high comment volume are not necessarily the most urgent trends. For example, while many people continue to discuss Gamestop, it's no longer a fresh trend that users can benefit from. HashHype applies a “decay” property which lets old trends fade away over time, then new fast moving trends display front and center.
Tech stack details
HashHype recycles many of the lessons learned during my work on HashBack, but simplifies and minifies along the way. At time of writing, HashHype is actively parsing comments from Reddit r/wallstreetbets and Twitter on a single Raspberry Pi computer. Many hours were spent analyzing memory/cpu usage, then iterating on code optimization, and persistence and caching techniques. Why? Let’s just say HashHype’s roadmap may involve hotspots to mine peer to peer information exchange.
In this project I got to wear the full stack hat. I did a good deal of custom coding for front end, back end, ops, and algo work. I even host the pi cluster in my own home with all kinds of redundancies and fail safes (this included me climbing onto our roof to install a 5G antenna - fun stuff). If anyone reading this wants to know more, buy me a beer and brace for max nerd mode.
Why did I pick this project?
We are observing a social evolution that is moving at an unexpected pace. Our modern methods of exchanging information have equated to so much more than just convenience or fun, they shape our existence and predict the future. I am particularly motivated to complete development on social trends before our next presidential election. I hope that my work will offer information that isn’t bound by ulterior motives, and simply helps us be ourselves.